
Warum Open Source trotz des Closed-Source-Ansatzes von OpenAI die Zukunft gehört
Weder zu ChatGPT noch zu GPT-4 hat OpenAI Details veröffentlicht, wie die Modelle erstellt wurden, was im Gegensatz zur bisher herrschenden Open-Source-Kultur in der KI-Forschung steht. Steffen Brandt von opencampus.sh ordnet die aktuellen Entwicklungen ein und verdeutlicht, warum wir aus seiner Sicht jetzt mit dem Aufsetzen eigener generativer Sprachmodelle beginnen sollten.
Die Woche, in der GPT-4 veröffentlicht wurde, ist wahrscheinlich eine der bisher bemerkenswertesten im Bereich der KI gewesen. Lior Sinclair, Gründer von AlphaSignal, einem der meistgelesenen Newsletter zu KI (Alpha Signal, 2023), hatte sie in einem Tweet wie folgt zusammengefasst (Abbildung 1):
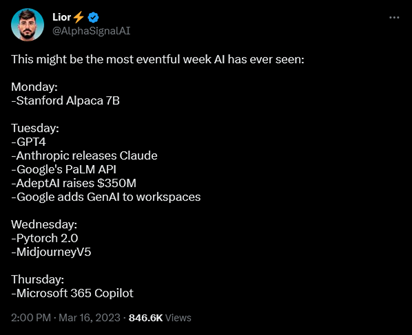
Abbildung 1: Tweet von Lior Sinclair (2023)
Die aufgezählten Ereignisse verdeutlichen, dass die Dynamik im Bereich der KI weit über GPT-4 hinausgeht. ChatGPT und GPT-4 von OpenAI sind nur die Speerspitze der Entwicklungen und ziehen die mediale Aufmerksamkeit auf sich. Tatsächlich ist aber insgesamt ein Momentum erreicht, das den Einsatz der KI-Modelle in unsere alltäglichen Anwendungen sinnvoll macht – am deutlichsten sichtbar durch die Integration in Office365 und Google Workspace (Spataro, 2023; Wright, 2023).
Zugleich hat die Woche durch die Veröffentlichung des Stanford Alpaca 7B Modells (Stanford Center for Research on Foundation Models, 2023) und des Modells Claude von Anthropic (2023) gezeigt, wie stark die Open-Source-Bewegung ist.
Open Source als Alternative
Das Stanford Alpaca Modell wurde als Open Source veröffentlicht und ist vergleichbar mit GPT-3.5. Es basiert auf dem von Meta ebenfalls als Open-Source zur Verfügung gestellten Modell LLaMA (Meta AI, 2023). Die Trainingsdaten für das Fine-Tuning wurden mit Hilfe von GPT-3.5 generiert und das Training des Modells hat weniger als 600 US-Dollar gekostet (Schreiner, 2023). Durch die Veröffentlichung des Modells werden zwei Dinge deutlich:
1. Die Ergebnisse der Modelle von OpenAI können genutzt werden, um Replikas der Modelle zu erstellen und
2. das Training großer Sprachmodelle ist wieder finanzierbar geworden.
OpenAI ist sich der Folgen dieser Möglichkeiten bewusst und hat in seinen Nutzungsbedingungen daher explizit verboten, die Ein- und Ausgaben seiner Modelle zu nutzen, um damit andere Modelle zu erstellen, die in Konkurrenz zu denen von OpenAI treten könnten. Die kommerzielle Nutzung des Alpaca-Modells wurde entsprechend von den Autor:innen ausgeschlossen. In der Praxis wird es für OpenAI jedoch womöglich schwierig werden, zu verhindern, dass entsprechende Modelle trainiert und geteilt werden.
Einer der aktuell wichtigsten Konkurrenten von OpenAI ist Anthropic, gegründet von ehemaligen OpenAI-Mitarbeitenden. Sie verließen das Unternehmen zu der Zeit, als Microsoft bei OpenAI einstieg (Moss, 2021). Das Modell Claude, das jetzt veröffentlicht wurde und von Notion bereits in seiner Software eingesetzt wird (Notion, 2023), soll in der Qualität vergleichbar zu ChatGPT sein. Die Modellgewichte selbst wurden nicht Open Source zur Verfügung gestellt. Anthropic hat jedoch die Architektur des Modells und wie es trainiert wurde detailliert beschrieben (Bai et al., 2022), sodass man es theoretisch nachtrainieren könnte. OpenAI hat ebenfalls einen über 90-seitigen Technical Report zu GPT-4 veröffentlicht (OpenAI, 2023), hat darin aber alle wichtigen Informationen zur Erstellung des Modells willentlich ausgelassen – was bereits zu entsprechenden Memes geführt hat (Abbildung 2):
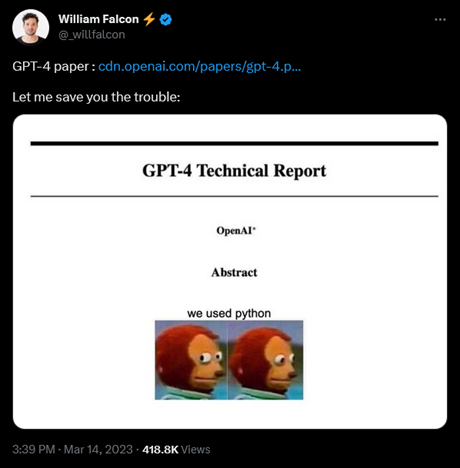
Abbildung 2: Tweet von William Falcon (2023)
Die Bibliotheken und Modelle, auf denen das Modell von OpenAI basiert, standen dem Unternehmen dagegen alle als Open Source zur Verfügung (größtenteils von Google entwickelt). Das Unverständnis gegenüber OpenAI ist in der KI-Community dadurch aktuell entsprechend stark.
Dem von OpenAI verfolgten Closed-Source-Ansatz stehen Organisationen wie Hugging Face und EleutherAI gegenüber.
Hugging Face wurde von drei Franzosen gegründet und ist trotz seines Sitzes in den Vereinigten Staaten ein stark europäisch geprägtes Unternehmen, das sich der Demokratisierung von KI verschrieben hat. So hat sich der Hugging Face Hub (Hugging Face, o. J.) in den letzten Jahren zur Standardplattform entwickelt, um Open-Source-Datensätze und -Modelle zu teilen und zu finden. Hugging Face entwickelt zudem zahlreiche Open-Source-Bibliotheken, die es ermöglichen, die jeweils aktuellsten Modelle mit grundlegenden Programmierkenntnissen selbst zu nutzen und nachzutrainieren (Hugging Face, 2022). Auch ermöglichen sie es, Rechenressourcen so effizient einzusetzen, dass das Training der Modelle bezahlbar ist (Beeching et al., 2023). Unterstützt wird Hugging Face durch Kooperationen mit Intel (Simon, 2022) oder AWS (Boudier, Schmid, & Simon, 2023). Diese profitieren dabei nicht durch einen exklusiveren Zugang zu den Modellen, sondern dadurch, dass neue, bessere Funktionsbibliotheken für den Einsatz auf den jeweiligen Chips bzw. Cloud-Service-Plattformen geschaffen werden, die damit deren Verwendung attraktiver machen.
Eine ähnliche Partnerschaft hat EleutherAI mit dem Cloud-Service-Provider CoreWeave (Kocher, 2022). EleutherAI ist ein Zusammenschluss von Forschenden, die sich über die Chat-Anwendung Discord kennengelernt haben und sich für eine offene KI-Forschung einsetzen. Als Kollektiv organisiert und in ihrer Freizeit umgesetzt haben sie den ersten Trainingsdatensatz in einer Größe ähnlich zu dem von GPT-3 und ein darauf trainiertes Modell veröffentlicht (Hjelm, 2022; ODSC-Open Data Science, 2021).
Der Open-Source-Gedanke ist stark in der KI-Forschung verwurzelt, und aktuell werden laufend neue Modelle und Trainingsdatensätze veröffentlicht. Eine neue Art von Trainingsdatensätzen sind dabei in den vergangenen Monaten solche zum Training von Sprachmodellen mit Human Feedback, dem Bereich, in dem OpenAI besondere Erfahrung hat und der ein relativ neuer Schwerpunkt in der Forschung ist. Dieses Training mit Human Feedback ist es, welches wesentlich über die Qualität der durch die Modelle generierten Antworten und deren Inhalte entscheidet (Christiano et al., 2023; Liu, Sferrazza, & Abbeel, 2023; Ouyang et al., 2022).
Julien Chaumond, CTO von Hugging Face, äußerte sich im Rahmen der Verkündigung der Zusammenarbeit mit AWS entsprechend positiv zur weiteren Entwicklung im Open-Source-Bereich: "[…] This is not about BLOOM or ChatGPT. This is about the dozens of BLOOMs and ChatGPTs that are going to be released by the community in the coming months, and years. […]" (2023). Keine drei Wochen später wurden die ersten Open-Source-Alternativen zu ChatGPT auf Hugging Face veröffentlicht (Abbildung 3).

Abbildung 3: Meme aus einem LinkedIn-Post von Jeff Boudier (2023)
Warum wir jetzt mit dem Aufsetzen eigener Modelle beginnen sollten
So wichtig es ist, innezuhalten und zu reflektieren, wie sich unsere Bildung, unsere Arbeitswelt und letztendlich unsere Gesellschaft durch KI verändern wird, so notwendig ist es auch, jetzt aktiv zu werden. Denn wie sich unsere Umwelt durch die eingesetzten Modelle verändern wird, hängt vor allem von uns selbst und den Modellen ab, die wir trainieren und nutzen.
Daher ist genau jetzt auch der Zeitpunkt, an dem Hochschulen, öffentliche Einrichtungen und große Unternehmen anfangen sollten, Erfahrungen mit selbst gehosteten Modellen zu sammeln. In technischer Hinsicht – um die Voraussetzungen für das Hosting zu schaffen – und aus inhaltlicher Sicht, um Wissen darüber aufzubauen, welche Modelle welche Eigenschaften besitzen oder auch welche Human-Feedback-Datensätze man nutzen kann, um Modelle mit den gewünschten Eigenschaften zu kreieren.
Im Bildungsbereich ist bereits absehbar, dass KI-Lernassistenten ein wichtiges Element unserer zukünftigen Bildungsformate sein werden (Duolingo Team, 2023; Khan, 2023). Womöglich bieten sie sogar die Chance zu einem gerechteren Bildungssystem (Kasneci, 2022). Voraussetzung dafür ist aber, dass wir Modelle einsetzen können, die datenschutzkonform, unbeeinflusst von kommerziellen Interessen und bestenfalls von öffentlichen Stellen gehostet oder zumindest zertifiziert sind.
Meine große Hoffnung ist, dass man an den entsprechenden Stellen jetzt über Ausschreibungen nachdenkt und in verschiedenen Bundesländern und an verschiedenen Hochschulen Projekte starten, um bald eigene Sprachmodelle für den Bildungsbereich zur Verfügung zu stellen.
Aus technischer Sicht sind die Möglichkeiten dazu gegeben.
Literatur
Alpha Signal. (2023). Alpha Signal | The weekly digest for AI Engineers and Researchers. Abgerufen 19. März 2023, von https://alphasignal.ai
Anthropic. (2023, März 14). Introducing Claude. Abgerufen 19. März 2023, von Anthropic website: https://www.anthropic.com/index/introducing-claude
Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., … Kaplan, J. (2022, Dezember 15). Constitutional AI: Harmlessness from AI Feedback. arXiv.
Beeching, E., Belkada, Y., Werra, L. von, Mangrulkar, S., Tunstall, L., & Rasul, K. (2023, März 9). Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU. Abgerufen 18. März 2023, von Blog website: https://huggingface.co/blog/trl-peft
Boudier, J. (2023, März 17). We now have 2️⃣ open source alternatives to ChatGPT on the 🤗 Hub! [..] [Post]. Abgerufen 18. März 2023, von LinkedIn website: https://www.linkedin.com/posts/jeffboudier_opensource-chatgpt-gpt4-activity-7042645661804105728-y-ok
Boudier, J., Schmid, P., & Simon, J. (2023, Februar 21). Hugging Face and AWS partner to make AI more accessible. Abgerufen 18. März 2023, von https://huggingface.co/blog/aws-partnership
Chaumond, J. (2023, Februar 26). Let’s make AI OPEN and not the other way around [...] [Feed]. Abgerufen 18. März 2023, von LinkedIn website: https://www.linkedin.com/feed/update/urn:li:activity:7034147214654349312/?updateEntityUrn=urn%3Ali%3Afs_feedUpdate%3A%28V2%2Curn%3Ali%3Aactivity%3A7034147214654349312%29
Christiano, P., Leike, J., Brown, T. B., Martic, M., Legg, S., & Amodei, D. (2023, Februar 17). Deep reinforcement learning from human preferences. arXiv.
Duolingo Team. (2023, März 14). Duolingo Max Uses OpenAI’s GPT-4 For New Learning Features. Abgerufen 18. März 2023, von Duolingo Blog website: https://blog.duolingo.com/duolingo-max/
Hjelm, M. (2022). CoreWeave Unlocks the Power of EleutherAI’s GPT-NeoX-20B — CoreWeave. Abgerufen 19. März 2023, von Company Announcements website: https://www.coreweave.com/blog/coreweave-unlocks-the-power-of-eleutherais-gpt-neox-20b
Hugging Face. (2022). The Hugging Face Course, 2022. Abgerufen von https://huggingface.co/course
Hugging Face. (o. J.). Hugging Face Hub documentation. Abgerufen 19. März 2023, von https://huggingface.co/docs/hub/index
Kasneci, E. (2022, Dezember 22). “ChatGPT can lead to greater equity in education”. Abgerufen 18. März 2023, von News and Events website: https://www.tum.de/en/news-and-events/all-news/press-releases/details/chatgpt-kann-zu-mehr-bildungsgerechtigkeit-fuehren
Khan, S. (2023, März 14). Harnessing GPT-4 so that all students benefit. A nonprofit approach for equal access—Khan Academy Blog. Abgerufen 18. März 2023, von Khan Academy website: https://blog.khanacademy.org/harnessing-ai-so-that-all-students-benefit-a-nonprofit-approach-for-equal-access/
Kocher, L. (2022, Februar 3). CoreWeave Partners With EleutherAI & NovelAI To Make Open Source AI. Abgerufen 19. März 2023, von Open Source For You website: https://www.opensourceforu.com/2022/02/coreweave-partners-with-eleutherai-novelai-to-make-open-source-ai-more-accessible/
Liu, H., Sferrazza, C., & Abbeel, P. (2023, März 5). Chain of Hindsight Aligns Language Models with Feedback. arXiv.
Meta AI. (2023, Februar 24). Introducing LLaMA: A foundational, 65-billion-parameter language model. Abgerufen 18. März 2023, von https://ai.facebook.com/blog/large-language-model-llama-meta-ai/
Moss, S. (2021, Juni 2). Eleven OpenAI employees break off to establish Anthropic, raise $124m. Abgerufen 19. März 2023, von AI Business website: https://aibusiness.com/verticals/eleven-openai-employees-break-off-to-establish-anthropic-raise-124m
Notion. (2023, März 14). Excited to celebrate with @AnthropicAI today as they launch their new AI assistant, Claude! Notion AI’s development was supported by Claude’s uniquely creative writing and summarization abilities. Learn more: Https://anthropic.com/index/introducing-claude https://t.co/LwSYieu1ly [Tweet]. Abgerufen 19. März 2023, von Twitter website: https://twitter.com/NotionHQ/status/1635675619085418498
ODSC-Open Data Science. (2021, Januar 25). The Pile Dataset: EleutherAI’s Massive Project to Help Train NLP Models. Abgerufen 19. März 2023, von Medium website: https://odsc.medium.com/the-pile-dataset-eleutherais-massive-project-to-help-train-nlp-models-76bdd6359f3c
OpenAI. (2023, März 16). GPT-4 Technical Report. arXiv.
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., … Lowe, R. (2022, März 4). Training language models to follow instructions with human feedback. arXiv.
Schreiner, M. (2023, März 17). Stanford’s Alpaca shows that OpenAI may have a problem. Abgerufen 18. März 2023, von THE DECODER website: https://the-decoder.com/stanfords-alpaca-shows-that-openai-may-have-a-problem/
Simon, J. (2022, Juni 15). Intel and Hugging Face Partner to Democratize Machine Learning Hardware Acceleration. Abgerufen 19. März 2023, von https://huggingface.co/blog/intel
Spataro, J. (2023, März 16). Introducing Microsoft 365 Copilot – your copilot for work. Abgerufen 19. März 2023, von The Official Microsoft Blog website: https://blogs.microsoft.com/blog/2023/03/16/introducing-microsoft-365-copilot-your-copilot-for-work/
Stanford Center for Research on Foundation Models. (2023, März 13). Alpaca: A Strong, Replicable Instruction-Following Model. Abgerufen 18. März 2023, von https://crfm.stanford.edu/2023/03/13/alpaca.html
William Falcon. (2023, März 14). GPT-4 paper: Https://cdn.openai.com/papers/gpt-4.pdf Let me save you the trouble: Https://t.co/zdsypRDHkx [Tweet]. Abgerufen 19. März 2023, von Twitter website: https://twitter.com/_willfalcon/status/1635712178031296520
Wright, J. V. (2023, März 14). Announcing new generative AI experiences in Google Workspace | Google Workspace Blog. Abgerufen 19. März 2023, von https://workspace.google.com/blog/product-announcements/generative-ai?hl=en





Steffen Brandt ist Diplom-Informatiker und promovierter Pädagoge und hat sich im Bildungsforschungsbereich in der Vergangenheit insbesondere mit der statistischen Modellierung beschäftigt. Aktuell ist er Projektleiter im gemeinnützigen Verein opencampus.sh und koordiniert dort das offene Bildungsprogramm im Bereich Machine Learning.